
![]()
Visual adversarial attacks and defenses
Deep neural networks (DNNs) have been shown to be successful in several vision tasks, such as image classification, object detection, semantic segmentation, optical flow estimation, and video classification. However, DNNs are sensitive to perturbations of the input data that produce the so-called adversarial examples that induce DNNs to erroneous predictions. The study of data alterations designed to evade a classifier is not new: techniques that mislead classifiers have been discussed for over two decades and include attacks on fraud detection systems, spam filters and on specific classifiers, such as Support Vector Machines. More recently, there has been a growing interest in adversarial examples for DNNs in visual tasks.
Adversarial examples in visual tasks are generated by modifying pixel values with carefully crafted additive noise that is imperceptible to the human eyes; or that replaces image regions (rectangular or circular) or the border of an image. Adversarial examples help investigate and improve the robustness of DNN models as well as protect private information in images. An adversarial attack can be targeted or untargeted. Targeted attacks modify an image or a video for the DNN model to predict a specified class label, such as an object type or a predefined object trajectory in subsequent frames. Untargeted attacks modify a source image or video to be classified as any incorrect label other than the original one, or the video perturbations can generate incorrect bounding boxes to mislead a tracker. Finally, carefully modified stop signs can cause a false negative detection or an incorrect detection of another object type.
The chapter Visual adversarial attacks and defenses in the book Advanced Methods And Deep Learning In Computer Vision presents the problem definition off adversarial attacks for visual tasks using both images and videos as input, their main properties and the types of perturbation they generate, as well as the target models and datasets used to craft adversarial attacks in the attack scenarios. Specifically, the chapter covers adversarial attacks for image processing tasks, image classification, semantic segmentation and object detection, object tracking, and video classification, as well as defenses devised against these adversarial attacks. In this webpage, we summarise the properties of the visual adversarial attacks and we provide the tables, extracted from the chapter, that summarise adversarial attacks for tasks that use images as input, adversarial attacks for tasks that use videos as input, and defenses against adversarial attacks.
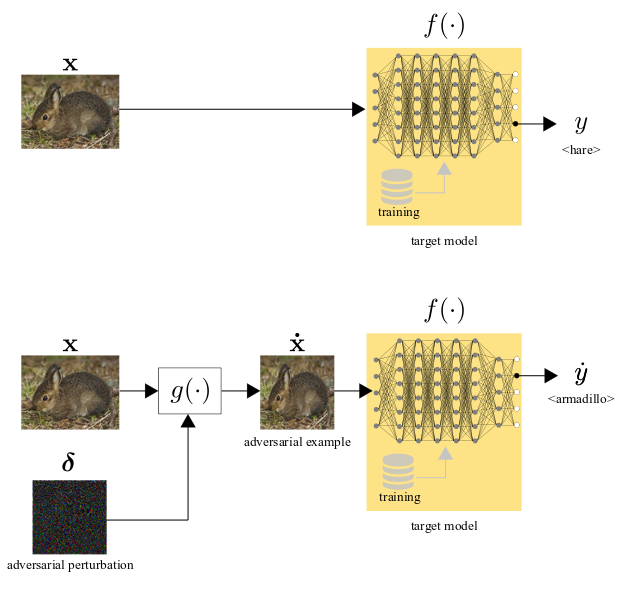
Illustrative example of adversarial attack for image classification. The original image is classified with the label hare by the target model (top), while the perturbed image (adversarial example), obtained with the Basic Iterative Method attack, is classified with the label armadillo by the same model (bottom). Note that the target model is an illustrative and abstract representation of the Inception V3 classifier that is trained on ImageNet. Note also that the magnitude of the perturbation is scaled up to 20 times larger than the real one for visualization purposes.
Do you want to include your attack or defense?
Submit the attack/defense using the link under the corresponding table!
Effectiveness
The effectiveness of an adversarial attack is the degree to which it succeeds in misleading a machine learning model. Effectiveness can be measured as the accuracy of the model over a target dataset. The lower the accuracy, the higher the effectiveness of an adversarial attack.
Robustness
The robustness of an adversarial attack is its effectiveness in the presence of a defense that removes the effect of the adversarial perturbation δ prior to the data being processed by the target model f(·). Examples of defense include median filtering, requantization, and JPEG compression. Robustness can be measured as the difference in accuracy of the target model over a target dataset when a defense is used with respect to a setting when the defense is not used for the target model. The smaller this difference, the higher the robustness of an adversarial attack.
Transferability
The transferability of an adversarial attack is the extent to which a perturbation δ crafted for a target model f(·) is effective in misleading another model that was not used to generate the advewrsarial perturbation δ. Transferability can be measured as the difference in accuracy of f (·) and f'(·) over a target dataset of adversarial examples crafted for the target model f(·). The smaller this difference, the higher the transferability of the attack to the classifier f'(·).
Noticeability
The noticeability of an adversarial attack is the extent to which an adversarial perturbation δ can be seen as such by a person looking at an image/video. Noticeability can be measured with a double stimulus test that compares image or video clip pairs; a single stimulus test on the naturalness of image or video clips controlled by the results obtained with the corresponding original image or video clip; or with a (reliable) no-reference perceptual quality measure.
In addition to these four main properties, other properties, such as detectability and reversibility, may be considered when analyzing or evaluating adversarial attacks for specific tasks or objectives.
Detectability
The detectability of an adversarial attack is the extent to which a defense mechanism is capable of identifying that a perturbation was applied to modify an original image, video, or scene. Detectability, which is related to robustness, can be measured as the proportion of adversarial examples that are detected as such in a given dataset or given scenarios. A (successful) defense can be used to determine the detectability of an attack by comparing the output of the target model f(·) on a given input and on the same input preprocessed with a defense, as different outputs suggest the presence of an attack.
Reversibility
The reversibility of an adversarial attack is the extent to which an analysis of the predictions or output labels of f(·) may support the retrieval of the original class of x˙. For instance, the analysis of the frequency of an adversarial-original prediction mapping revealed that untargeted attacks are more reversible than targeted attacks.
Mouse over the reference link of each row to see the details of the publication or work (this does not work for mobile devices).
Mouse over the reference link of each row to see the details of the publication or work (this does not work for mobile devices).
Mouse over the reference link of each row to see the details of the publication or work (this does not work for mobile devices).
If you use any content from this page, please cite the following reference:
C. Oh, A. Xompero, and A. Cavallaro, Visual adversarial attacks and defenses, in Advanced Methods And Deep Learning In Computer Vision, Editors: E. R. Davies, Matthew Turk, 1st Edition, Elsevier, pages 511-543, November 2021.
If you have any enquiries, contact us at [cis-web@eecs.qmul.ac.uk].