Audio-visual sensing from a quadcopter: dataset and baselines
for source localization and sound enhancement
Lin Wang, Ricardo Sanchez-Matilla, Andrea Cavallaro
Queen Mary University of London - Centre for Intelligent Sensing
We present an audio-visual dataset recorded outdoors from a quadcopter and discuss baseline results for multiple applications. The dataset includes a scenario for source localization and sound enhancement with up to two static sources, and a scenario for source localization and tracking with a moving sound source. These sensing tasks are made challenging by the strong and time-varying ego-noise generated by the rotating motors and propellers. The dataset was collected using a small circular array with 8 microphones and a camera mounted on the quadcopter. The camera view was used to facilitate the annotation of the sound-source positions and can also be used for multi-modal sensing tasks. We discuss the audio-visual calibration procedure that is needed to generate the annotation for the dataset, which we make available to the research community.
The dataset consists of two subsets, namely S1 and S2, and two types of scenarios, namely natural and composite. S1 includes sound sources at fixed locations, whereas S2 includes moving sound sources.
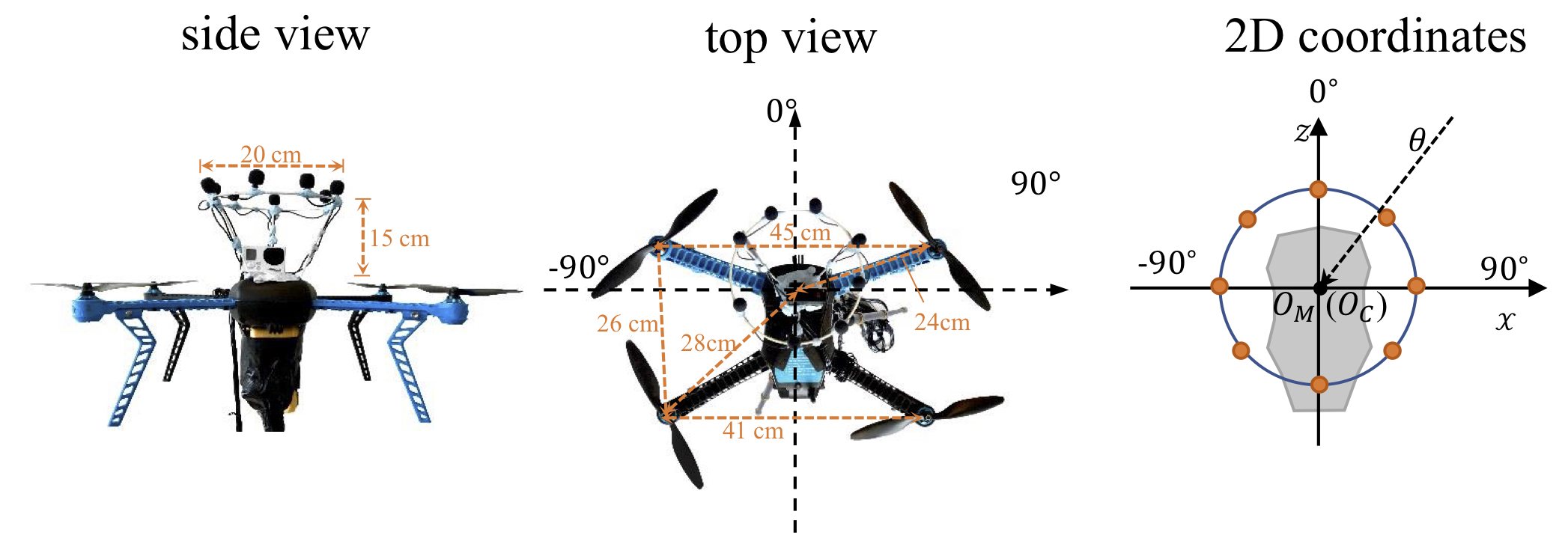
Side and top view of the audio-visual sensing platform; and 2D-coordinate system. OM and OC denote the centres of the microphone array and of the camera in the 2D plane, respectively.
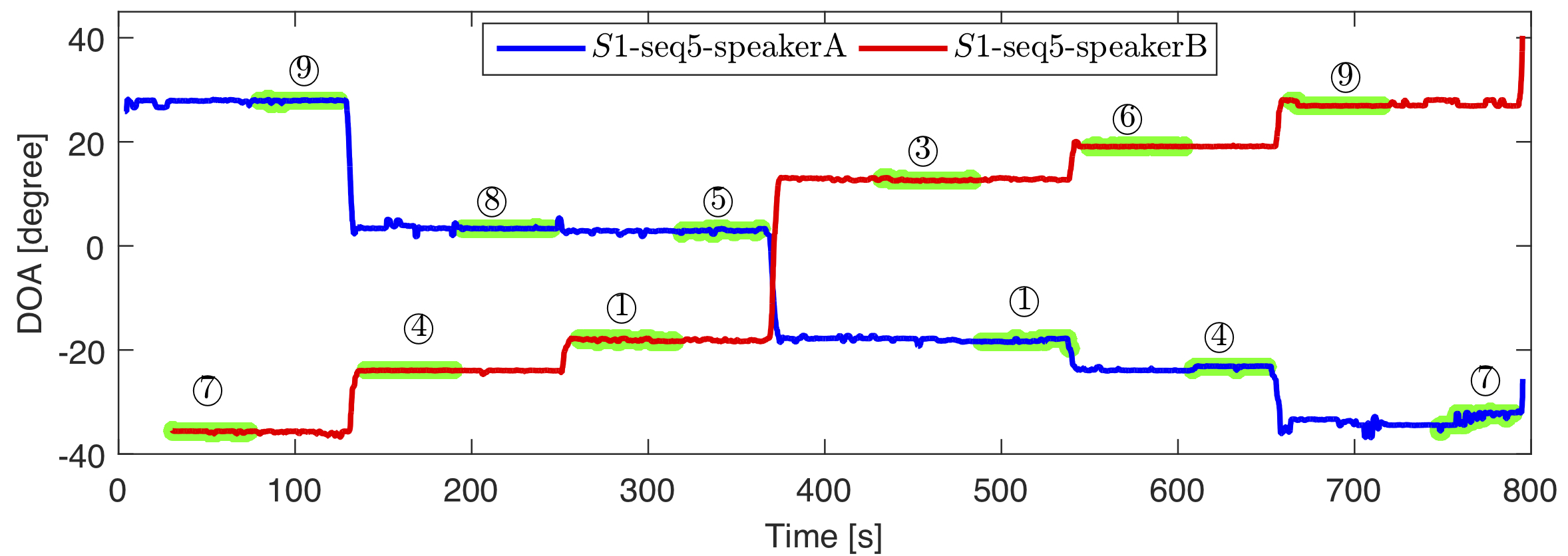
Scenario 1:
Two people talk from nine locations.
The left panel depictes the recording setup. The middle panel shows the layout where the persons move with respect to the quadcopter and an example frame from the onboard camera. The right panel shows ground-truth trajectories.
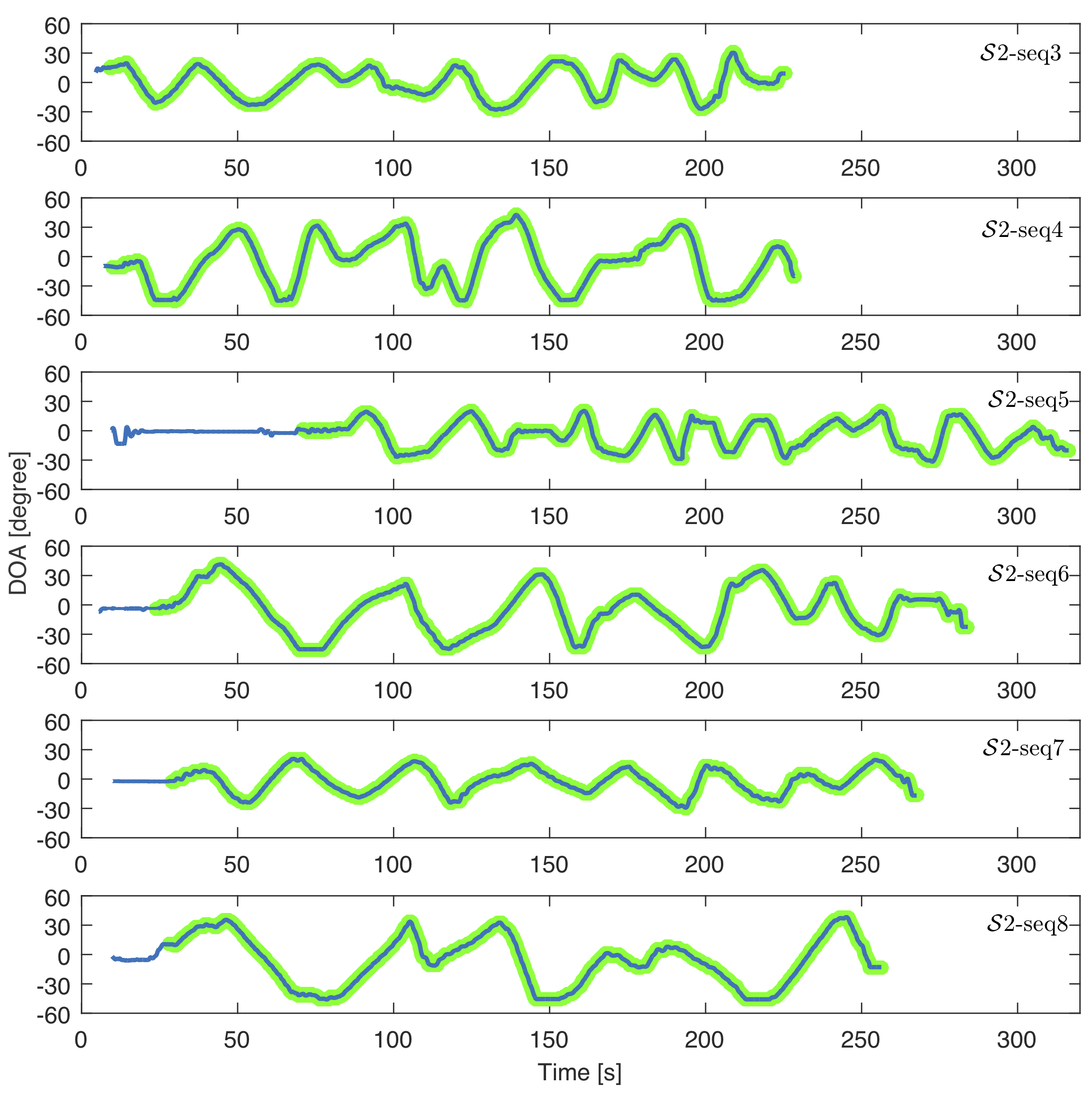
Scenario 2:
A loudspeaker is carried by a person walking in front of the drone.
The left panel depictes the recording setup. The middle panel shows the layout where the loudspeaker moves and a sample frame from the onboard camera. The right panel shows ground-truth trajectories.
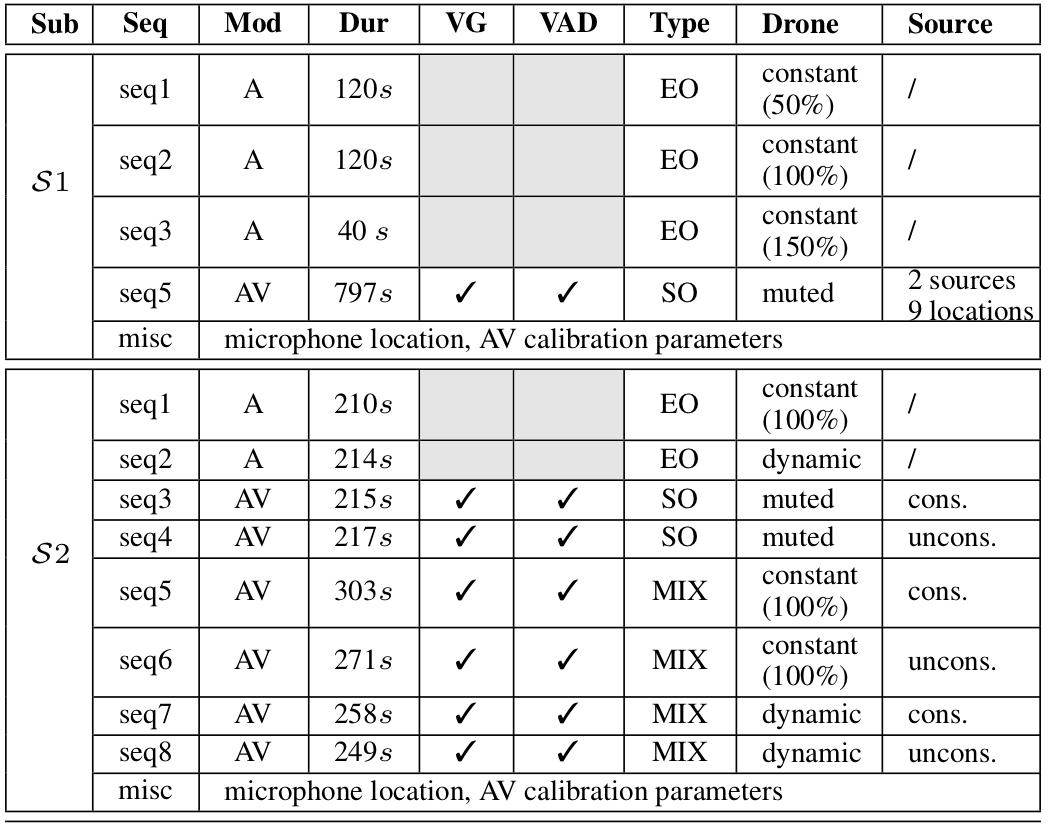
Specifications:
Table summarizes the specifications of the AVQ dataset.
KEY - Sub: Subset; Seq: Sequence; Mod. Modality; Dur: Duration; VG: Video ground-truth; VAD: voice activity detection; A: Audio-only; AV: Audio-visual; EO: ego-noise only; SO: speech only; MIX - mixture; cons: constrained area; uncons: unconstrained area; misc: miscellaneous.